Introduction
A way organizations deal with the progression towards a more connected and API driven world, is by implementing a lightweight SOA/REST API architecture for application services to simplify the delivery of modern apps and services.
In the following blog series, we're going to show how solutions based on 3scale and Red Hat JBoss Fuse enable organizations to create right interfaces to their internal systems thus enabling them to thrive in the networked, integrated economy.
Among the API Management scenarios that can be addresses by 3cale and Red Hat with JBoss Fuse on OpenShift, we have selected to showcase the following:
• Scenario 1 – Fuse on Openshift with 3scale on Amazon Web Services (AWS)
/2015/02/apimanagement-fuse-3scale-scenario1.html • Scenario 2 – Fuse on Openshift with APICast (3scale’s cloud hosted API gateway)
/2015/02/apimanagement-fuse-3scale-scenario2.html • Scenario 3 – Fuse on Openshift and 3scale on Openshift
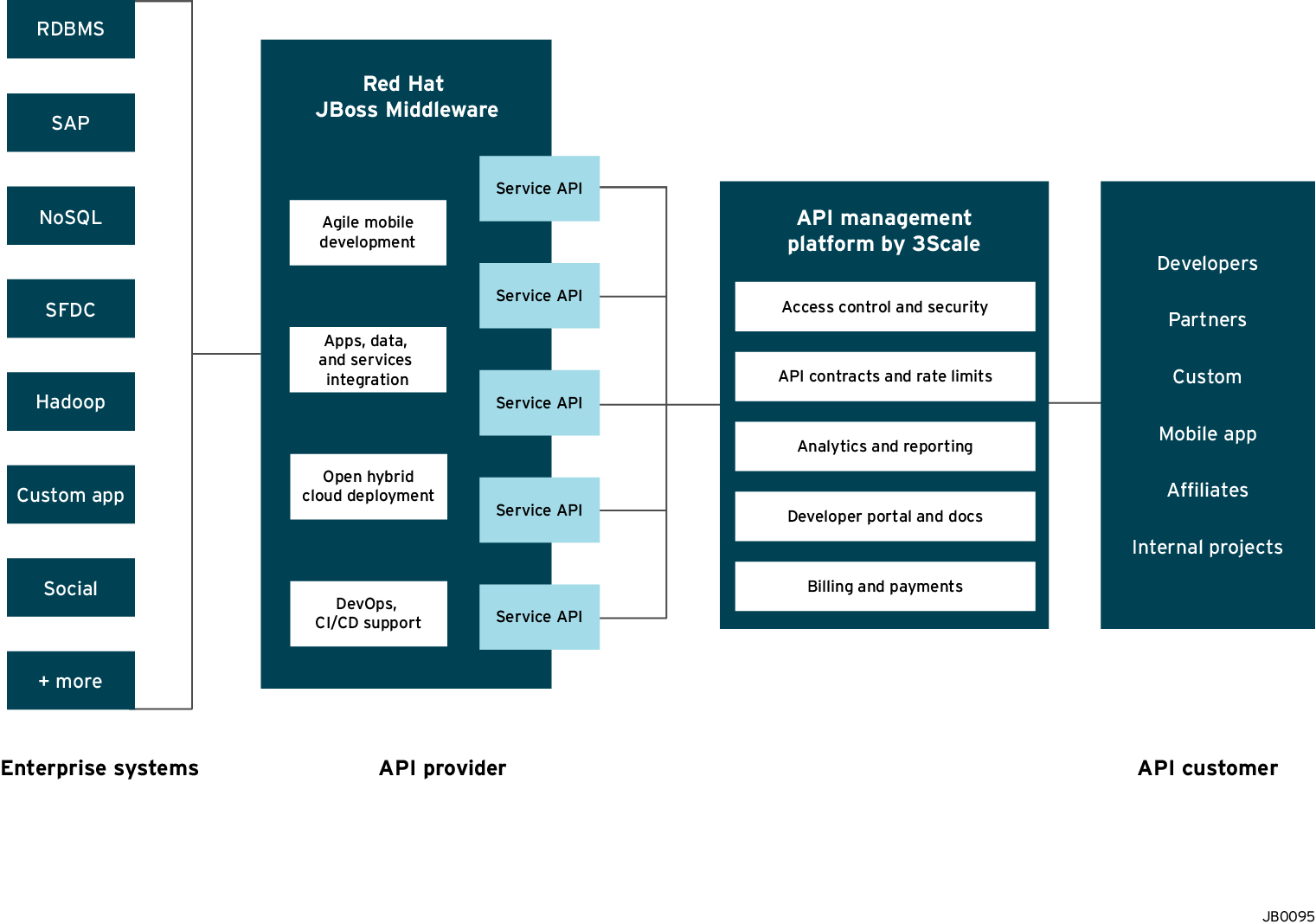
/2015/02/apimanagement-fuse-3scale-scenario3.htmlThe illustration below depicts an overview of the 3scale API Management solution integrated with JBoss. Conceptually the API Management sits in between the API backend that provides the data, service or functionality and the API Consumers (developers) on the other side. The 3scale API Management solution subsumes: specification of access control rules and usage policies (such as rate limits), API Analytics and reporting, documentation of the API on developer portals (including interactive documentation), and monetization including end-to-end billing.
This article covers scenario 1 which is 3scale on AWS and Fuse on Openshift. We split this article into four parts:
- Part 1: Fuse on Openshift setup to design and implement the API
- Part 2: 3scale setup for API Management using the nginx open-source API gateway
- Part 3: Openshift setup for API gateway hosting
- Part 4: Testing the API and API Management NOTE: If you followed Article 1 and/or 2 for this series then Part 1 and Part 2 should already be done for you and you can start at Part 3.
Part 1: Fuse on Openshift setup
We will create a Fuse Application that contains the API to be managed. We will use the REST Quickstart that is included with Fuse 6.1. This requires a Medium or Large gear to be used as using the small gear will result in out of memory errors and/or horrible performance.
Step 1: Sign onto your Openshift Online Account. You can sign up for a Openshift Online account if you don’t have one.
Step 2: Click the Add Application button after singing on.
Step 3: Under xPaaS select the Fuse type for the application
Step 4: Now we will configure the application. Enter a Public URL, such as restapitest which gives the full url as appname-domain.rhcloud.com. As in the example below restapitest-ossmentor.rhcloud.com. Change the gear size to medium or large which is required for the Fuse cartridge. Now click on Create Application.
Step 5: Click Create Application
Step 6: Browse to the application hawtio console and sign on
Step 7: After signing on click on the Runtime tab and the container. We will add the REST API example.
Step 8: Click on Add a Profile button
Step 9: Scroll down to examples/quickstarts and click the rest checkbox then add. The REST profile should show on the container associated profile page.
Step 10: Click on the Runtime/APIs tab to verify the REST API profile.
Step 11: Verify the REST API is working. Browse to customer 123 which will return the ID and name in XML format.
Part 2: 3scale setup
Once we have our API set up on Openshift we can start setting it up on 3scale to provide the management layer for access control and usage monitoring.
Step 1: Log in to your 3scale account. You can sign up for a 3scale account for free at
www.3scale.net if you don’t already have one. When you log in to your account for the first time you will see a to-do list to guide you through setting up your API with 3scale.

Step 2: If you click on the first item in the list “Add your API endpoint and hit save & test” you’ll be taken directly to the 3scale Integration page where you can enter the public url for your Fuse Application on Openshift that you have just created, e.g restapitest-ossmentor.rhcloud.com and click on “Update & test.” This will test your set up against the 3scale sandbox proxy. The sandbox proxy allows you to test your 3scale set up before deploying your proxy configuration to AWS.

Step 3: The next step is to set up the API methods that you want to monitor and rate limit. You will do this by creating Application Plans that define which methods are available for each type of user and any usage limits you want to enforce for those users. You can get there from the left hand menu by clicking Application Plans.
and clicking on one of the Application Plans set up by default for your account. In this case we will click on “Basic.”
Which will take you to the following screen where you can start creating your API methods
for each of the calls that users can make on the API:
e.g Get Customer for GET and Update Customers for PUT / etc…
Step 4: Once you have all of the methods that you want to monitor and control set up under the application plan, you will need to map these to actual http methods on endpoints of your API. We do this by going back to the Integration page and expanding the “Mapping Rules” section.
And creating proxy rules for each of the methods we created under the Application Plan.
Once you have done that, your mapping rules will look something like this:
Step 5: Once you have clicked “Update and Test” to save and test your configuration, you are ready to download the set of configuration files that will allow you to configure your API gateway on AWS. As an API gateway we use an high-performance and open-source proxy called
nginx. You will find the necessary configuration files for nginx in the same Integration page, by scrolling down to the “Production” section
The final section will now take you through installing these configuration files on your Nginx instance on OpenShift.
Part 3: NGINIX on OpenShift Instance
We assume that you have already completed these steps:
- You have your Openshift account.
- You have created your application and are ready to deploy it to Openshift.
- You have created your proxy on 3scale.
With that accomplished we are ready to setup our Openshift Application and deploy our configuration.
Step 1: Create an application with the DIY cartridge, either with the client tools (rhc) or through the console.
Step 2: Stop the Openshift Application with so you do not get port binding errors, ie. rhc app stop diytestnginix --namespace ossmentor
Step 3: Use SSH to get t the OpenShift shell, ie ssh
[email protected]Step 4: Setup an the PATH variable for ldconfig or you will get the PATH env when enabling luajit error, ie export PATH=$PATH:/sbin
Step 5: Install the PCRE module
- cd $OPENSHIFT_TMP_DIR
- wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.36.tar.bz2
- tar jxf pcre-8.36.tar.bz2
Step 6: Install and build the nginix-openresty package
- wget http://openresty.org/download/ngx_openresty-1.7.7.1.tar.gz
- tar xzvf ngx_openresty-VERSION.tar.gz
- cd ngx_openresty-1.7.7.1
- ./configure --prefix=$OPENSHIFT_DATA_DIR --with-pcre=$OPENSHIFT_TMP_DIR/pcre-8.36 --with-pcre-jit --with-ipv6 --with-http_iconv_module -j2
- Run gmake
- Run gmake install
Step 7: Go to 3scale and download the nginx config proxy_configs.zip which contains the conf and lua files
Step 8: Copy the two files to the openshift application to the $OPENSHIFT_TMP_DIR using scp, ie. scp nginx_2445581129832.lua
[email protected]:/tmp/nginix_2445581129832.lua
Step 9: Copy the files to the nginx conf directory, ie cp $OPENSHIFT_TMP_DIR/nginix_244* $OPENSHIFT_DATA_DIR/nginx/conf
Step 10: Rename and Update the nginx.conf file
use the mv command to change the nginx config to nginx.conf
Run env to get OPENSHIFT_DIY_IP and OPENSHIFT_DIY_PORT
Change the Server, IP and port
listen 127.13.112.1:8080;
## CHANGE YOUR SERVER_NAME TO YOUR CUSTOM DOMAIN OR LEAVE IT BLANK IF ONLY HAVE ONE
#server_name diytestnginix-ossmentor.rhcloud.com;
Change the lua file name
## CHANGE THE PATH TO POINT TO THE RIGHT FILE ON YOUR FILESYSTEM IF NEEDED
access_by_lua_file /var/lib/openshift/54c6763fe0b8cd8484000020/app-root/data/nginx/conf/nginix_2445581129832.lua;
Step 11: Start nginx from $OPENSHIFT_DATA_DIR/nginx/sbin
./nginx /var/lib/openshift/54c6763fe0b8cd8484000020/app-root/data/nginx/sbin/nginx -p $OPENSHIFT_DATA_DIR/nginx/ -c $OPENSHIFT_DATA_DIR/nginx/conf/nginx.conf
STEP 12: If you need to stop nginx use ./nginx -s stop
Part 4: Testing the API and API Management
Use your favorite REST client and run the following commands
1. Retrieve the customer instance with id 123
http://54.149.46.234/cxf/crm/customerservice/customers/123?user_key=b9871b41027002e68ca061faeb2f972b
2. Create a customer
http://54.149.46.234/cxf/crm/customerservice/customers?user_key=b9871b41027002e68ca061faeb2f972b
3. Update the customer instance with id 123
http://54.149.46.234/cxf/crm/customerservice/customers?user_key=b9871b41027002e68ca061faeb2f972b
4. Delete the customer instance with id 123
http://54.149.46.234/cxf/crm/customerservice/customers/123?user_key=b9871b41027002e68ca061faeb2f972b
5. Check the analytics of the API Management of your API
If you now log back in to your 3scale account and go to Monitoring > Usage you can see the various hits of the API endpoints represented as graphs.
This is just one element of API Management that brings you full visibility and control over your API. Other features are:
- Access control
- Usage policies and rate limits
- Reporting
- API documentation and developer portals
- Monetization and billing
For more details about the specific API Management features and their benefits, please refer to the
3scale product description.
For more details about the specific Red Hat JBoss Fuse Product features and their benefits, please refer to the
Fuse Product description.
For more details about running Red Hat JBoss Fuse on OpenShift, please refer to the
xPaaS with Fuse on Openshift description.