|
| http://www.redhat.com/en/files/resources/en-rhjb-ventana-research-infographic.pdf |
One of the great capabilities of JBoss Data Virtualization is the ability to connect to Hadoop through Hive which was added as part of Data Virtualization (DV) 6.0. This gives us the ability to aggregate data from multiple datasources that include big data. This also gives us the ability to analyze our data through many different tools and standards. From the
Re-Think Data Integration infographic, more than one-quarter
of companies see
virtualizing data as a
critical approach to
integrating big data. With DV 6.1 Cloudera Impala was added for fast SQL query access to data stored in Hadoop. So I wanted to add an example of how to use Cloudera Impala as a Data Source for DV. To find out how Cloudera Impala fits into the Hadoop ecosystem take a look at the
Impala Concepts and Architecture documentation.
Differences between Hive and Impala
First let's take a look at an overview of Hive and Impala. Cloudera Impala is a native Massive Parallel Processing (MPP) query engine which enables users to perform interactive analysis of data stored in HBase or HDFS. The Apache Hive data warehouse software facilitates querying and managing large data sets residing in distributed storage and provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. I grabbed some of the information from the
Cloudera Impala FAQ.
How does Impala compare to Hive (and Pig)? Impala is different from Hive because it uses its own daemons that are spread across the cluster of queries. Since Impala does not rely on MapReduce it avoices the startup overhead of MapReduce jobs which allows Impala to return results in real time.
Can any Impala query also be executed in Hive? Yes. There are some minor differences in how some queries are handled, but Impala queries can also be completed in Hive. Impala SQL is a subset of HiveQL. Impala is maintained by Cloudera while Hive is maintained by Apache.
Can I use Impala to query data already loaded into Hive and HBase? There are no additional steps to allow Impala to query tables managed by Hive, whether they are stored in HDFS or HBase. Impala is configured to access the Hive metastore.
Is Hive an Impala requirement? The Hive metastore service is a requirement. Impala shares the same metastore database as Hive, allowing Impala and Hive to access the same tables transparently. Hive itself is optional.
What are good use cases for Impala as opposed to Hive or MapReduce? Impala is well-suited to executing SQL queries for interactive exploratory analytics on large data sets. Hive and MapReduce are appropriate for very long running batch-oriented tasks such as ETL.
Cloudera Setup
There are several options that Cloudera offers to test their product. There are quickstart VMs, Cloudera Live and Local install for CDH. For quick setup I chose a quick start
Virtual Box Virtual Machine for CDH 5.4.x for a single-node Hadoop Cluster with examples for easy learning. The VMs run CentOS 6.4 and are available for VMWare, VirtualBox and KVM. All of them require 64-bit host OS. I also chose a bridged network, increased the memory and CPUs. Once the VM is downloaded you extract the files from the ZIP, import the VM and make network/memory/CPU setting changes. Then the VM can be started.
Once you launch the VM, you are automatically logged in as the cloudera user. The account details are:
- username: cloudera
- password: cloudera
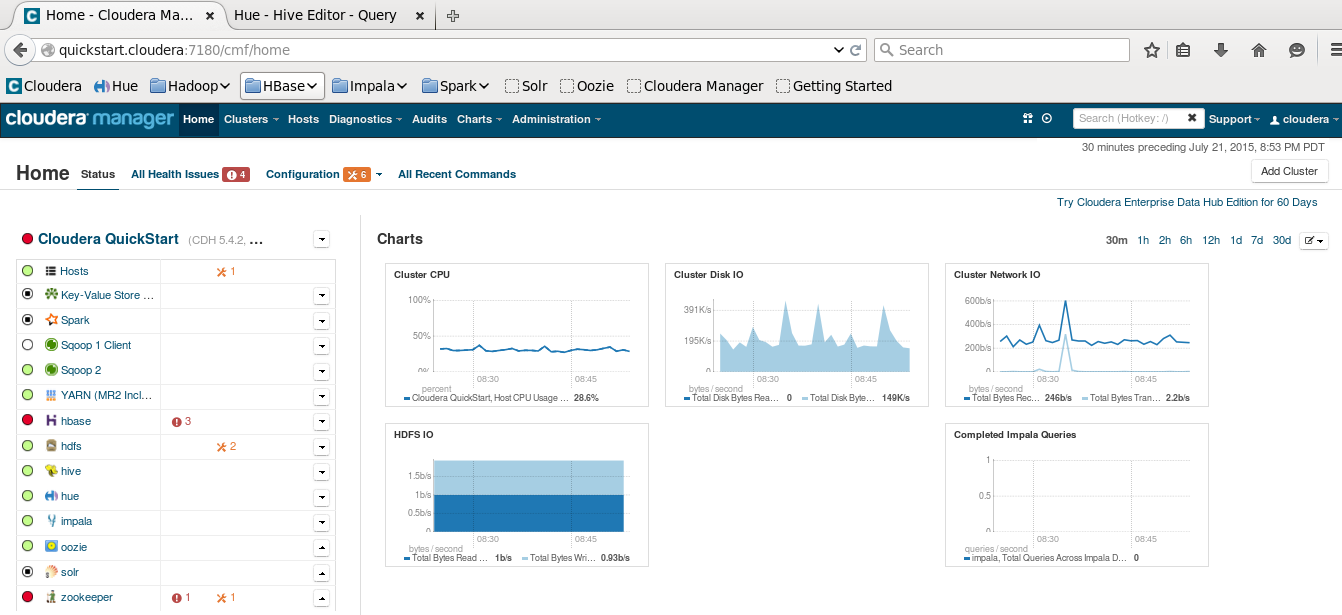
The cloudera account has sudo privileges in the VM. The root account password is cloudera. The root MySQL password (and the password for other MySQL user accounts) is also cloudera. Hue and Cloudera Manager use the same credentials. Then we want to browse to the Cloudera Manager at quickstart.cloudera:7180/cmf/home. We want to make sure our services are started such as Impala, Hive, YARN, etc.
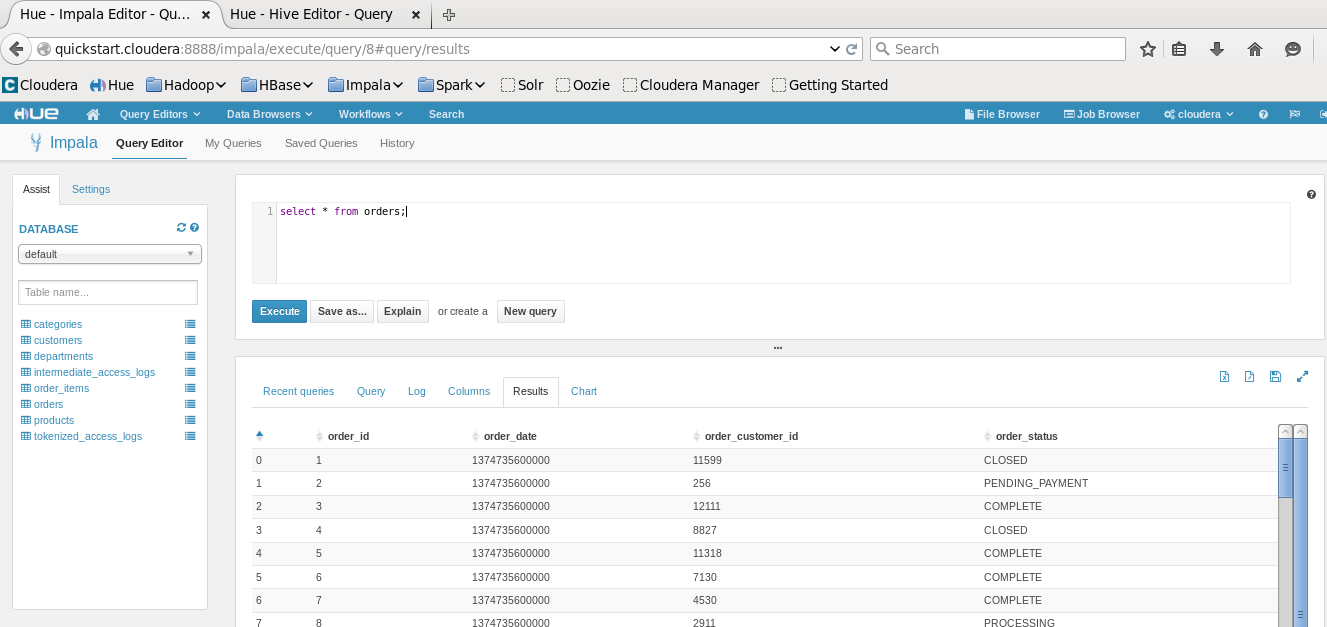
Now that we have the VM setup we want to make sure we can add data. I ran through Cloudera's Tutorial Exercise 1-3 at quickstart.cloudera/tutorial/home. Then we can see the tables and data through the Hue UI (quickstart.cloudera:8888) through impala and hive.
Now we have our Big Data Environment running so let's move onto testing Impala and Hive.
SQuirreL Testing
SQuirreL SQL Client is a free open source graphical SQL client written in Java that will allow you to view the structure of a JDBC compliant database, browse the data in tables, issue SQL commands etc. First we have to download the JDBC drivers for Impala and Hive. First we will go through Impala in SQuirrel. I downloaded the
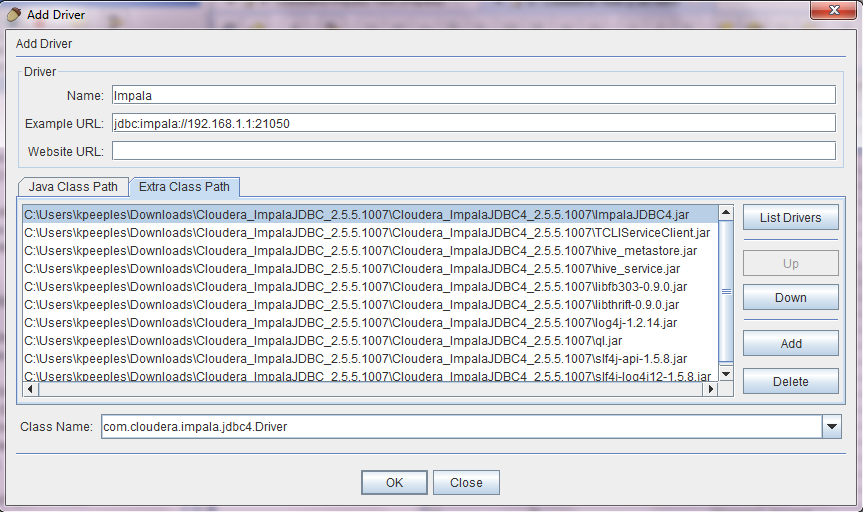
Impala JDBC v2.5.22 driver. Then I unzipped the jdbc4 zip file. We add the JDBC driver by clicking on the drivers tab, then the add driver button. In the extra class path tab click on Add, browse to the extracted jar files and add them along with the Name and Class Name.
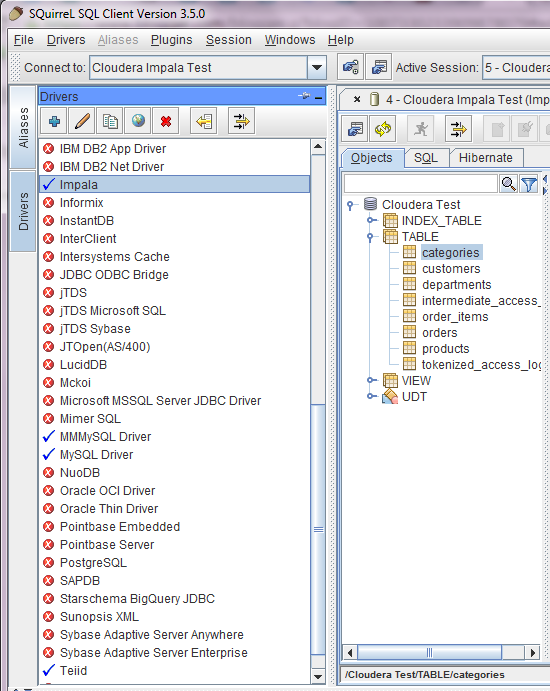
Once the driver is added the driver should have a green check mark.
Next we click on the Aliases tab and add a new connection.
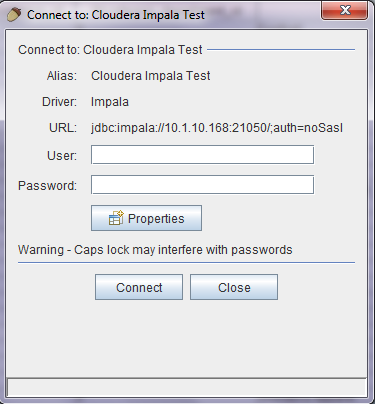
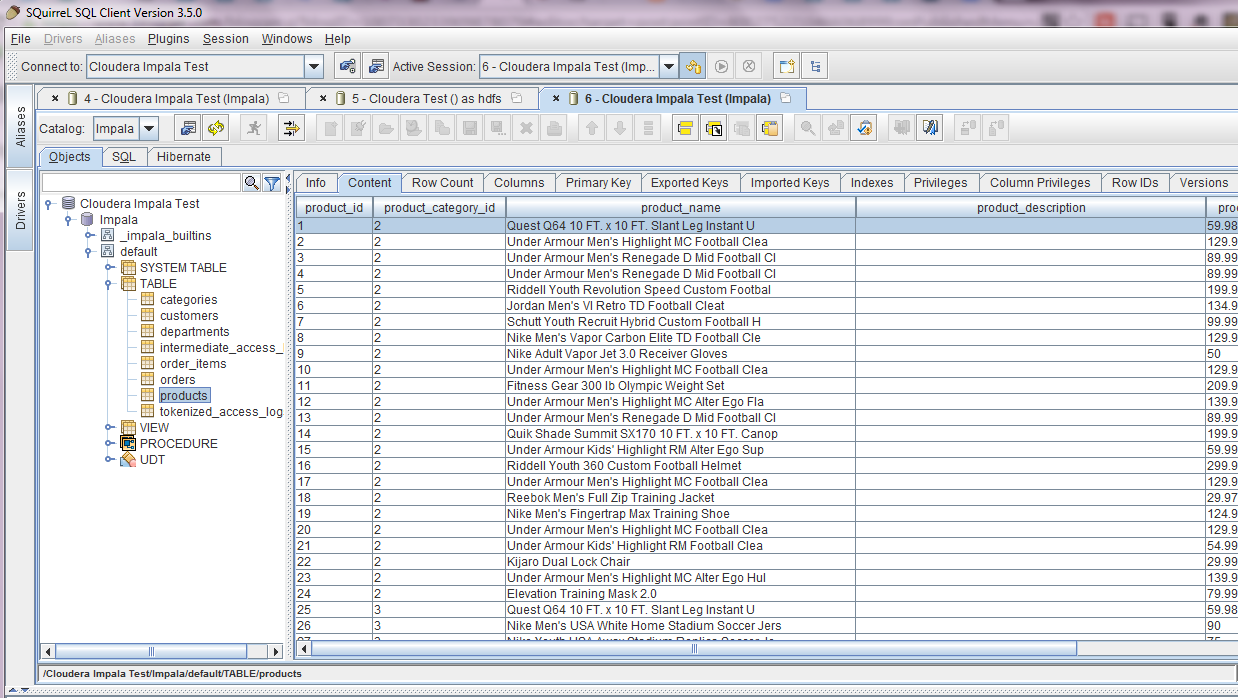
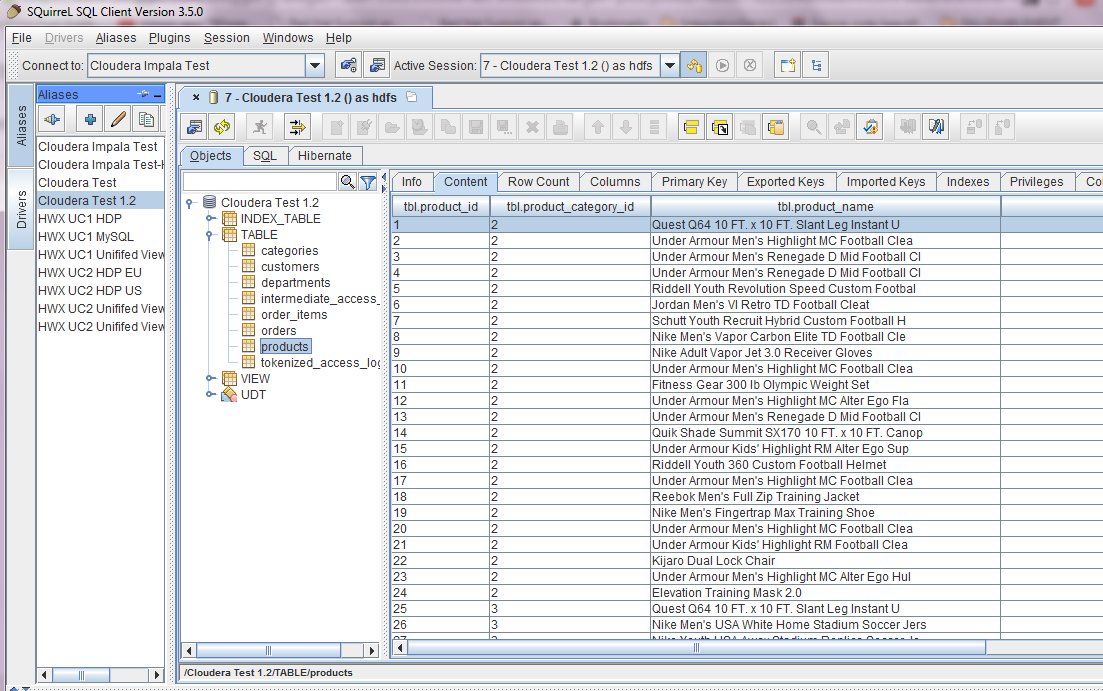
We add the driver and URL and then click connect. Once connected we can browse to the tables, select a table and preview content.
Now we have previewed the data through Impala through SQuirreL. Now we want to test Hive as well. We download the Hive 1.2.1 driver from
Hive Apache. We do the same as above and add the driver by pointing to the jars in the lib directory of the download and use Driver Class org.apache.hive.jdbc.HiveDriver. Once the driver is added then we create a session connecting to Hive.
We can view the tables and content which shows we can now use Hive and Impala through DV to access the data in Cloudera.
Data Virtualization Testing
Now we can move onto testing Cloudera Impala with DV. DV 6.1 GA can be downloaded from
jboss.org. We will also use
JBoss Developer Studio and the
JBoss Integration Stack.
Data Virtualization Setup
Run through the DV install instructions to install the product. Then we want to update the files for the Cloudera Impala JDBC driver.
To configure the Cloudera's Impala as datasource with DV
1) Make sure the server is not running.
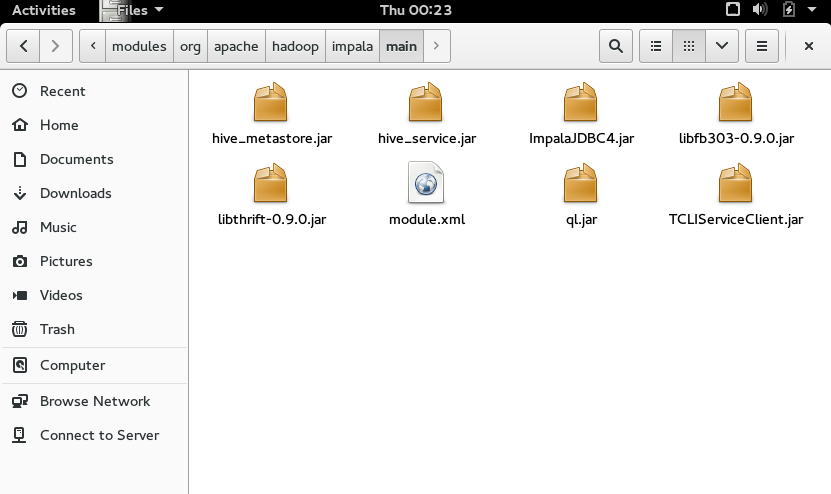
2) In the modules directory create the org/apache/hadoop/impala/main folder.
3) Within the folder we want to create the module.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<module xmlns="urn:jboss:module:1.0" name="org.apache.hadoop.impala">
<resources>
<resource-root path="ImpalaJDBC4.jar"/>
<resource-root path="hive_metastore.jar"/>
<resource-root path="hive_service.jar"/>
<resource-root path="libfb303-0.9.0.jar"/>
<resource-root path="libthrift-0.9.0.jar"/>
<resource-root path="TCLIServiceClient.jar"/>
<resource-root path="ql.jar"/>
</resources>
<dependencies>
<module name="org.apache.log4j"/>
<module name="org.slf4j"/>
<module name="org.apache.commons.logging"/>
<module name="javax.api"/>
<module name="javax.resource.api"/>
</dependencies>
</module>
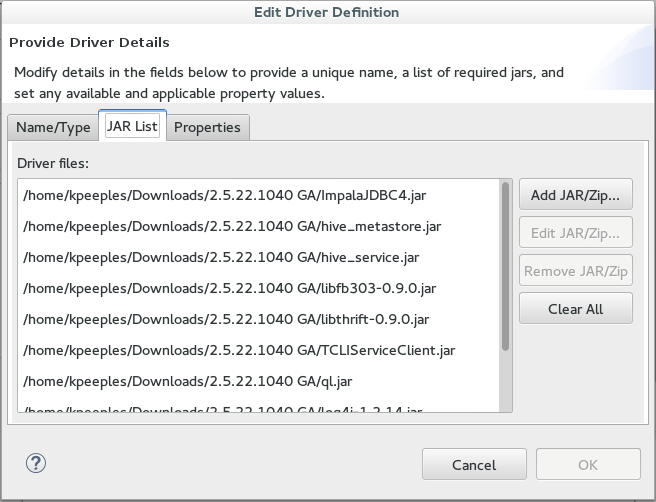
Note that the resources points to the jar files included with the Impala driver.
4) Now copy the above JDBC jar files in the resources section to the folder.
5) Next we update the standalone.xml file in the standalone/configuration folder. The driver and datasource can be added.
<datasource jndi-name="java:/impala-ds" pool-name="ImpalaDS" enabled="true" use-java-context="true">
<connection-url>jdbc:impala://10.1.10.168:21050/;auth=noSasl</connection-url>
<driver>impala</driver>
</datasource>
<driver name="impala" module="org.apache.hadoop.impala">
<driver-class>com.cloudera.impala.jdbc4.Driver</driver-class>
</driver>
6) Now we can start the server
JBoss Developer Studio Setup
Run through the install instructions for installing the JBoss Developer Studio and installing the Teiid Components from the Integration Stack. Create a new workspace, ie dvdemo-cloudera. Then we will create a example view.
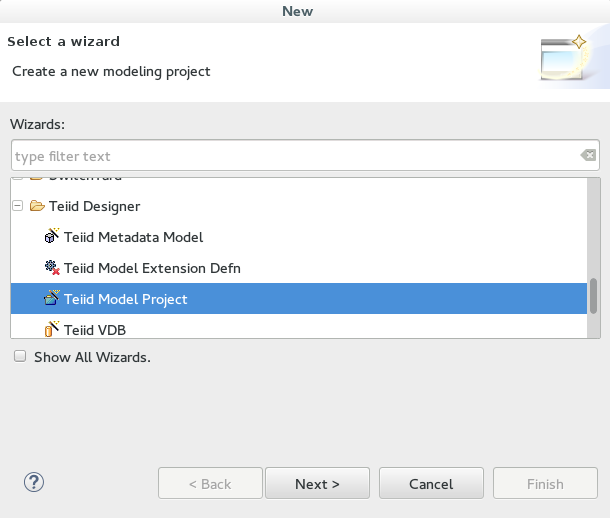
1. Create a New Teiid Model Project, ie clouderaimpalatest
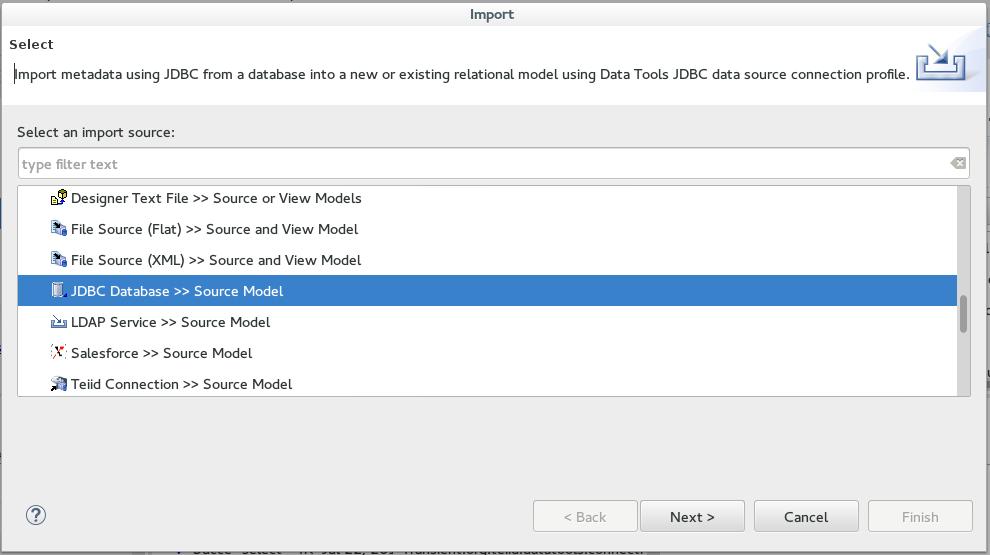
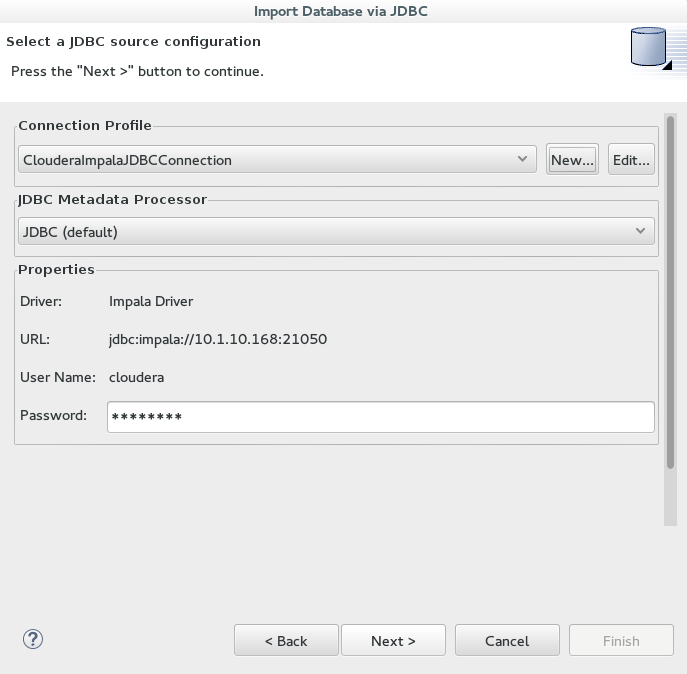
2. Next Import metadata using JDBC from a database into a new or existing relational model using Data Tools JDBC data source connection profile.
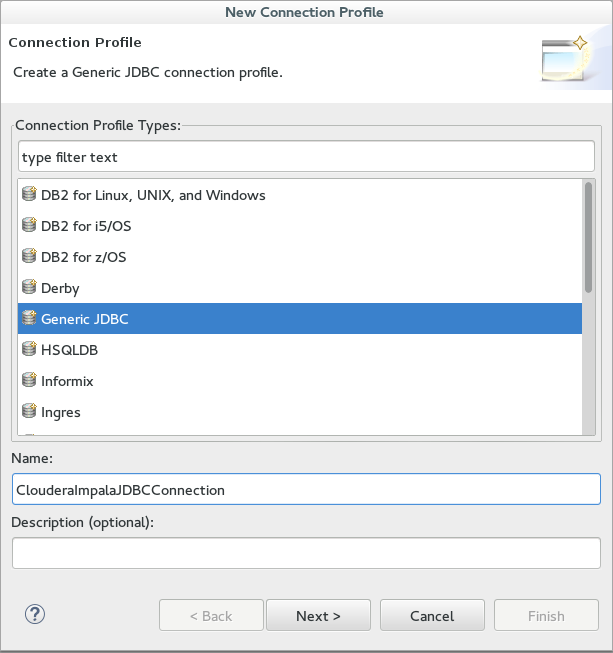
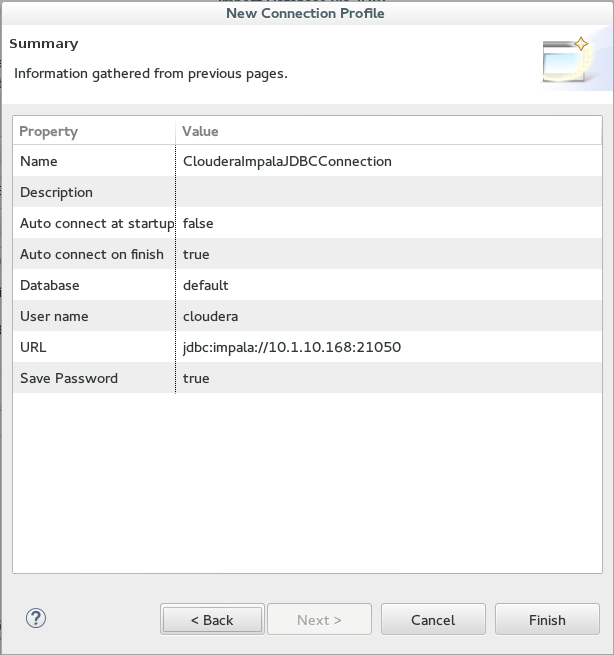
3. Next we create a new connection profile with the Generic JDBC Profile Type.
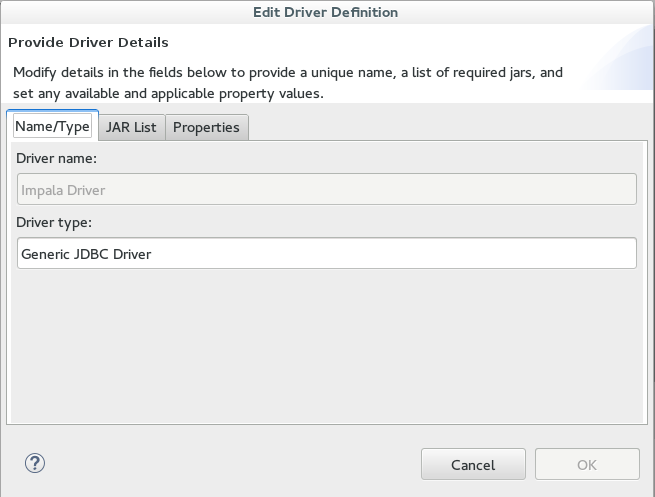
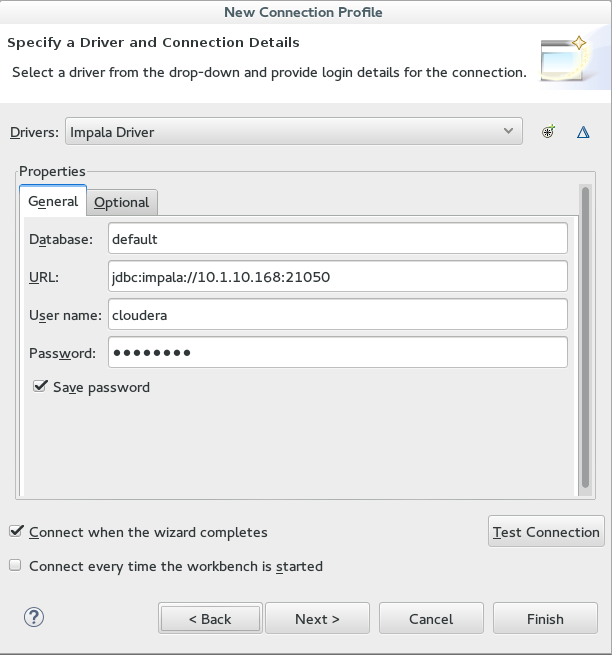
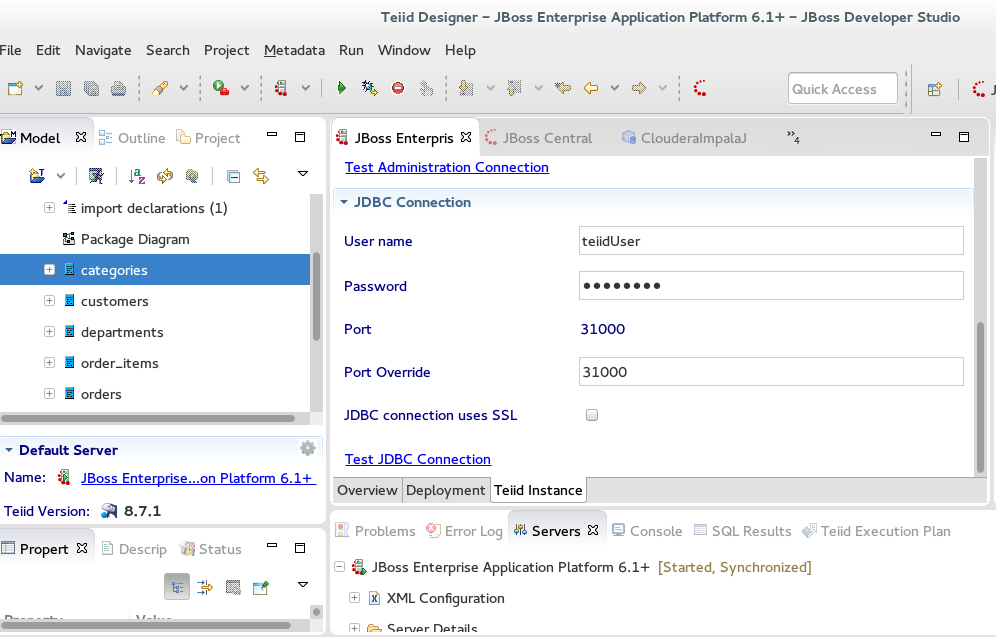
4. We create a new driver, ie Impala Driver, by adding all the jars and setting the connection settings. The username/password should be ignored.
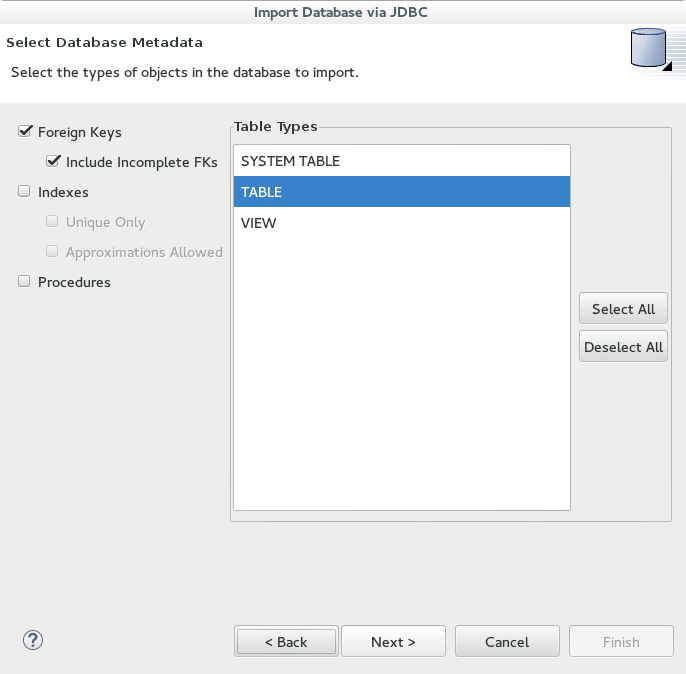
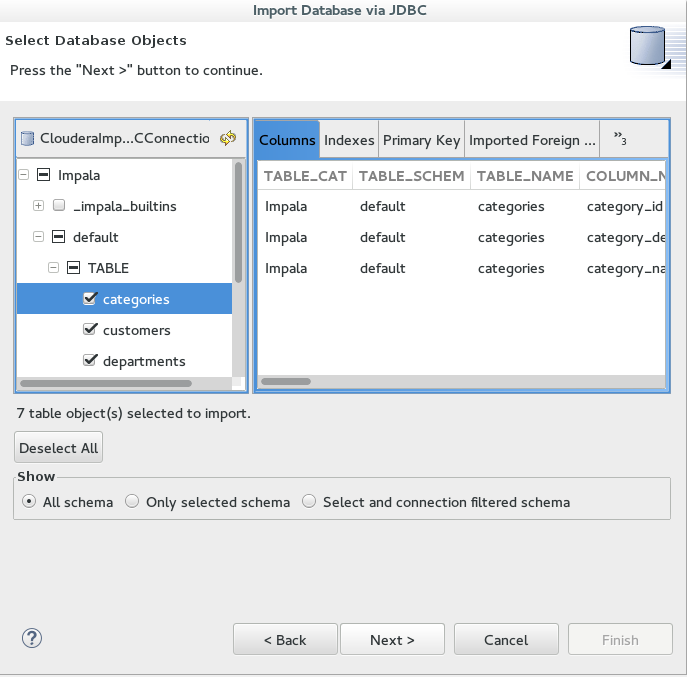
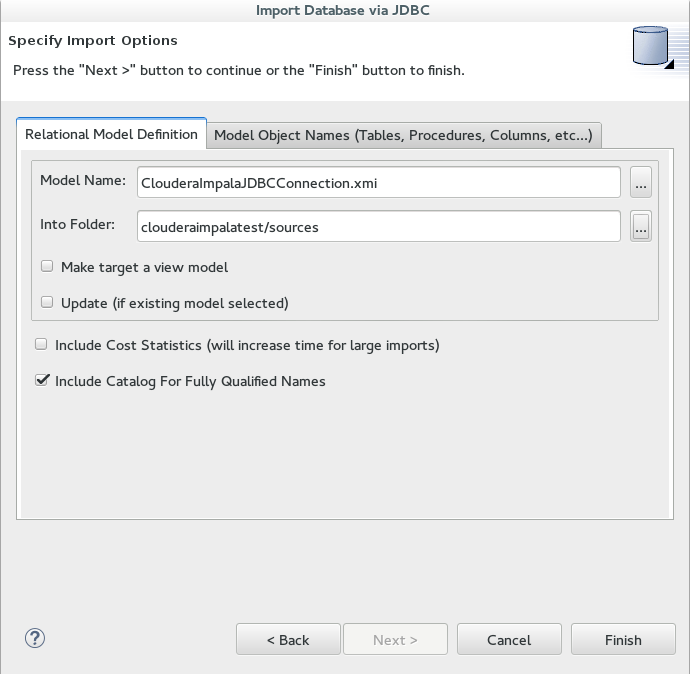
5. Next we import the metadata and select the types of objects in the database to import. We will just choose the tables and then the sources folder.
6. We add a new server and set it as externally managed. We start the server externally and then click the start button within JBDS,
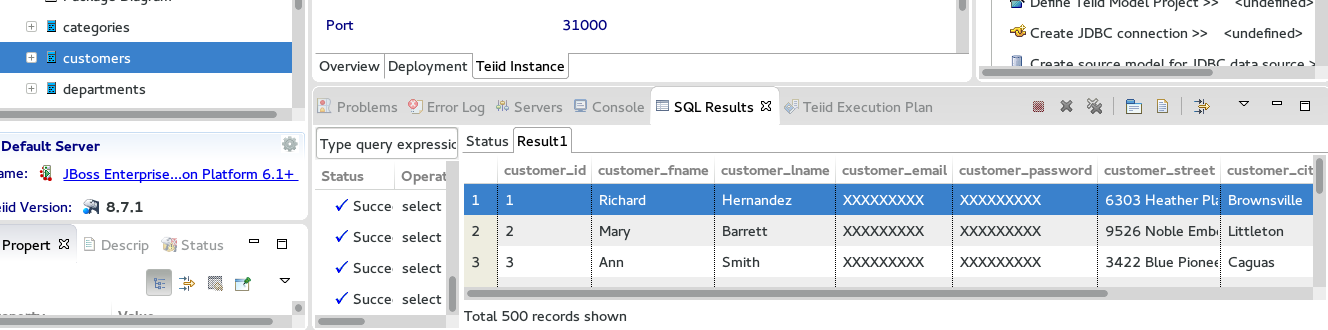
7. Within the sources folder in the Teiid Perspective we right click one of the tables then Modeling and Preview Data. If everything is setup properly then Data will display.
8. Now we can create a layer or View to add an abstract layer. In our case we are just going to create a View for a one to one to Source example. But to show the power of DV we would normally aggregate or federate multiple sources into a view either in this layer or create another layer above that uses the lower layers for greater abstraction and flexibility. We will test with the customers table. After creating our view with table we tie the source table to the view. We also set the primary key on the customerid so when we create the VDB OData is available. We can also preview the data on the view.
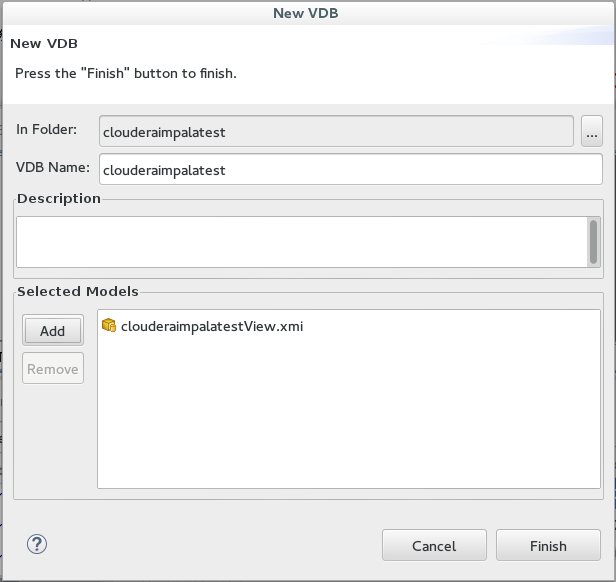
9. We create a VDB that we can deploy and execute to the server.
10. After right clicking on the clouderaimpalatest.vdb we click on deploy so it is deployed to the server. Next we can browse to the OData to show the data as a consumer.
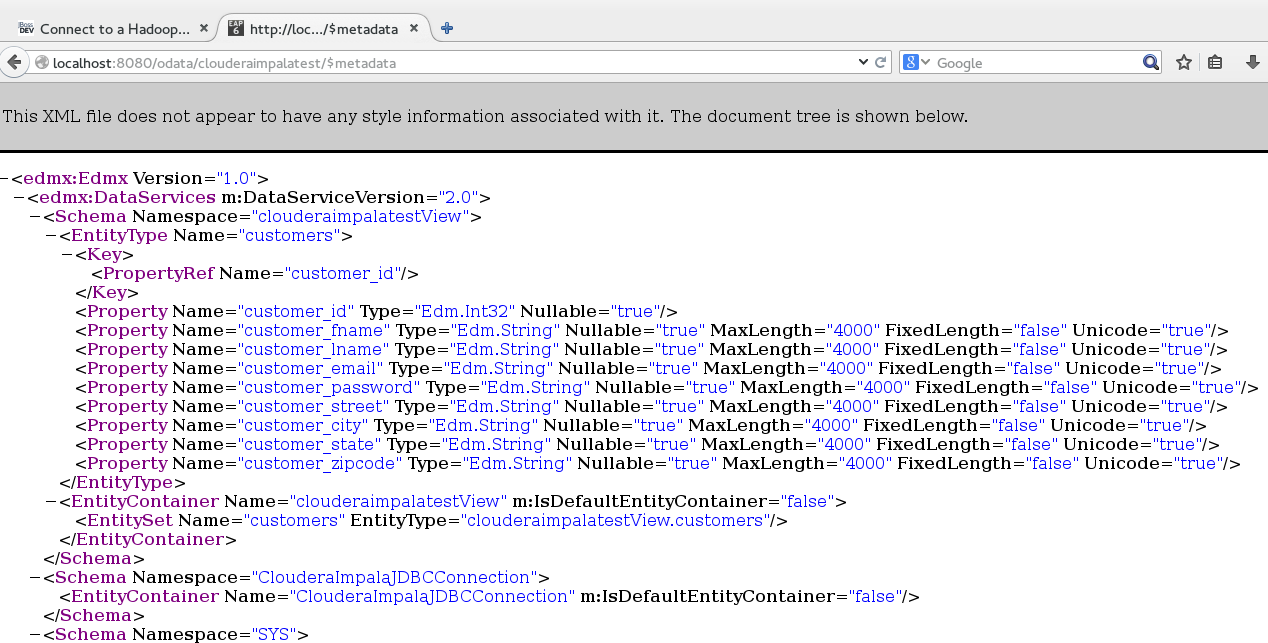
-First we take a look at the metadata
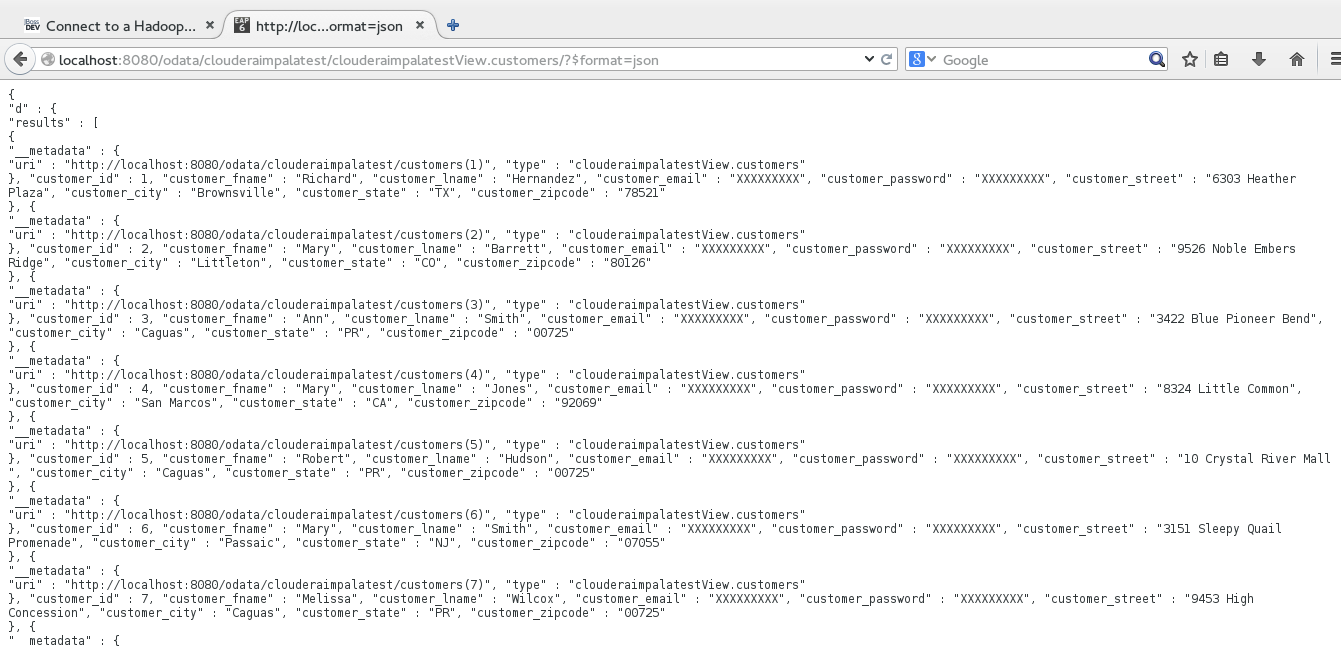
-Then we can list all the customers
References
https://hive.apache.org/
https://developer.jboss.org/wiki/ConnectToAHadoopSourceUsingHive2
http://www.cloudera.com/content/cloudera/en/downloads/connectors/impala/jdbc/impala-jdbc-v2-5-5.html
https://github.com/onefoursix/Cloudera-Impala-JDBC-Example