In this article we have a guest author, Rich Lucente. Rich is a Red
Hat Pre-sales engineer focusing on middleware and cloud computing
initiatives for federal government customers. He is going to discuss
Geo-spatial processing capabilities with Open Source Products which
include Fuse, BRMS, Data Virtualization and EAP. You can find Rich on
Linkedin at https://www.linkedin.com/profile/view?id=50013729 or email at [email protected].
Overview
Geo-spatial processing permeates the Department of Defense (DoD) with many solutions offered for tasks such as sensor and track fusion and correlation. Geo-spatial tasks encompass a specialized knowledge domain, often requiring input from subject matter experts for an effective solution. This article offers recommendations to modernize geo-spatial applications by leveraging current features and capabilities in popular open source products. This does not go into sufficient detail to create a "fully baked" solution since that would require fully understanding the prerequisites, dependencies, and having access to key stakeholders and existing software capabilities.
A number of DoD programs have expressed an interest in modernization and Red Hat believes that several products in our middleware portfolio can be a key foundation to this effort. Each product will be briefly described below with its applicability to this problem domain.
Red Hat JBoss Fuse 6.1
Red Hat JBoss Fuse 6.1 includes Apache Camel 2.12.0, which enables the definition of "routes" that specify chains, or pipelines, of activity on a message as it flows from a producer to a consumer. These routes can include mediation, transformation, and various other processors. Out of the box, Apache Camel includes a broad range of components that implement the protocols for endpoints. Examples include common endpoints like filesystems, file transfer protocol (FTP), as well as more complicated interfaces like java database connectivity (JDBC) and web services (both REST and SOAP).
Traditional application and data flow when processing sensor measurements and tracks can be externalized into camel routes, enabling a more flexible processing solution. The highly specialized processing for sensor and track fusion and correlation can still be embodied in specialized libraries that are accessed via custom message processors and/or custom camel components. This approach provides more modularity by bubbling up the processing flow to a higher abstraction layer.
These routes can be combined with specialized geo-spatial persistence stores like PostGIS or MySQL with geo-spatial extensions. Since camel components already exist for database interactions, this enables the results of the specialized library components to be persisted to geo-spatial data stores. Camel routes can manage the flow of the data through a larger integrated system including subsystems and subcomponents that persist sensor measurement, track data, and correlation/fusion statistics into geo-spatial and other data sources.
Red Hat JBoss Business Rules Management System 6.1
Within complex specialized problem domains, many decision points exist on the type of data, the results of various statistical tests, and other heuristics to optimize the processing of the data. These decisions are often buried in the implementation of the various libraries and sometimes are duplicated across software components, complicating any modernization and maintenance efforts.
Red Hat Business Rules Management System (BRMS) 6.1 specifically addresses the need to externalize various logical decisions into a versioned rules knowledgebase. Facts can be asserted into the knowledge session and then rules can be applied to prune the solution search space and create inferences on the data. This externalization of key decision logic enables more flexibility and modularity in implementations.
Fusion and correlation algorithms for sensor measurements and tracks are replete with heuristics and decision logic to optimize the processing of this data. Rather than bury decisions within the library implementations, BRMS can enable externalization of those decision points, providing for a greater level of flexibility in how tracks and sensor measurements are processed.
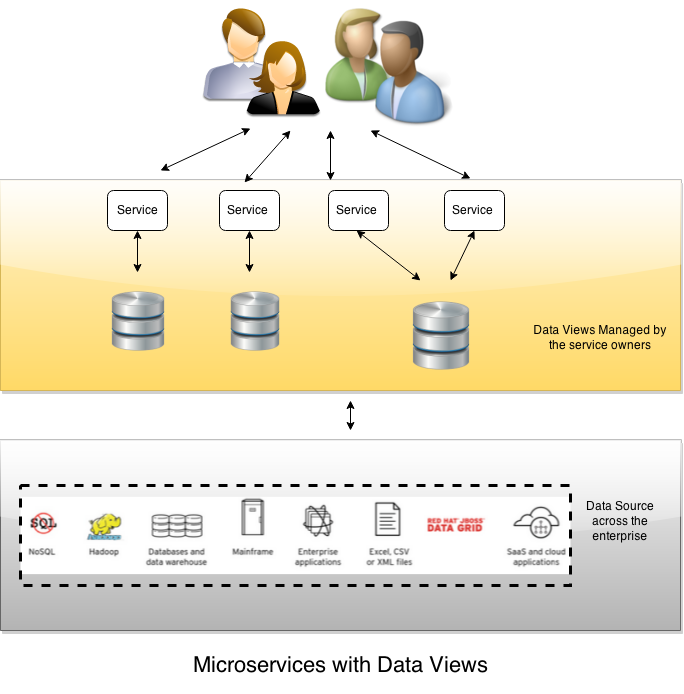
Red Hat JBoss Data Virtualization 6.1
Red Hat JBoss Data Virtualization (DV) 6.1 enables federation of multiple physical data sources into a single virtual database which may be exposed to an application as one more logical views. Client applications can access each view as a web service (REST or SOAP), JDBC/ODBC connection, or OData (using Atom XML or JSON). The DV tool offers an optimized query engine and a broad range of connectors to efficiently execute queries to populate the views.
Additionally, DV enables native query pass-throughs [1] to the underlying physical data source for those data sources that provide specialized query capabilities. For example, databases with geo-spatial extensions can execute specialized queries like whether one object contains another. By using query pass-throughs the DV query engine will not attempt further processing of the query but instead pass it as-is to the underlying geo-spatial datasource. This pass-through query processing can be combined with standard SQL queries from other data sources so that DV can provide a highly customizable, flexible data access layer for client applications. This data access layer can then be accessed as JDBC/ODBC, REST/SOAP web services and OData sources.
The Oracle and MongoDB translators within DV 6.1 also support geo-spatial operators. Specifically, the MongoDB translator [2] supports geo-spatial query operators in the "WHERE" clause, when the data is stored in the GeoJSon format in the MongoDB Document. These functions are supported:
- CREATE FOREIGN FUNCTION geoIntersects (columnRef string, type string, coordinates double[][]) RETURNS boolean;
- CREATE FOREIGN FUNCTION geoWithin (ccolumnRef string, type string, coordinates double[][]) RETURNS boolean;
- CREATE FOREIGN FUNCTION near (ccolumnRef string, coordinates double[], maxdistance integer) RETURNS boolean;
- CREATE FOREIGN FUNCTION nearSphere (ccolumnRef string, coordinates double[], maxdistance integer) RETURNS boolean;
- CREATE FOREIGN FUNCTION geoPolygonIntersects (ref string, north double, east double, west double, south double) RETURNS boolean;
- CREATE FOREIGN FUNCTION geoPolygonWithin (ref string, north double, east double, west double, south double) RETURNS boolean;
The Oracle translator [3] supports the following geo-spatial functions:
- CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 string, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 Object, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_relate (arg1 string, arg2 Object, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_relate (arg1 Object, arg2 string, arg3 string) RETURNS string;
- Nearest_Neighbor = dso_nn
- CREATE FOREIGN FUNCTION sdo_nn (arg1 string, arg2 Object, arg3 string, arg4 integer) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 Object, arg3 string, arg4 integer) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_nn (arg1 Object, arg2 string, arg3 string, arg4 integer) RETURNS string;
- Within_Distance = sdo_within_distance
- CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 Object, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_within_distance (arg1 string, arg2 Object, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_within_distance (arg1 Object, arg2 string, arg3 string) RETURNS string;
- Nearest_Neighbour_Distance = sdo_nn_distance
- CREATE FOREIGN FUNCTION sdo_nn_distance (arg integer) RETURNS integer;
- CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 string, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_filter (arg1 Object, arg2 Object, arg3 string) RETURNS string;
- CREATE FOREIGN FUNCTION sdo_filter (arg1 string, arg2 object, arg3 string) RETURNS string;
Hibernate Search in Enterprise Application Platform (EAP)
Besides the above, a canvas of activities across Red Hat show that the handling of geo-spatial information is also incorporated into other products. Hibernate Search, which is part of Red Hat JBoss Enterprise Application Platform (EAP) and the Red Hat JBoss Web Framework Kit (WFK), implements geo-spatial query capabilities atop Apache Lucene. The implementation enables either a classical range query on longitude/latitude or a hash/quad-tree indexed search when the data set is large.
Other programs within the Department of Defense are actively applying Red Hat technology as well. Programs often leverage EAP as well as Apache Tomcat and Apache httpd within Enterprise Web Server to connect to backends in MySQL and MongoDB for basic track fusion and geo-spatial processing/querying and displaying tracks on a map.
Conclusion
Geo-spatial processing is a key component of many DoD systems, at both the strategic and tactical level. This article presented some alternatives to traditional implementations to more flexibly implement solutions that leverage features and capabilities in modern software frameworks.
To find out more examples and articles on each of the products you can also check out the resources from the Technical Marketing Managers:
EAP/JDG - Thomas Qvarnström - @tqvarnst
DV/Feedhenry - Kenny Peeples - @ossmentor
BRMS/BPMS - Eric D. Schabell - @ericschabell
Fuse/A-MQ - Christina Lin - @christina_wm